
When I reviewed 2026 enterprise AI documentation and regulatory updates, one pattern stood out: accuracy is no longer the primary differentiator in RAG systems—traceability is. Retrieval-Augmented Generation is now judged not just by whether it answers correctly, but whether it can prove where the answer came from.
That shift changes everything.
A RAG pipeline is still about retrieval plus generation. But in 2026, it is increasingly about attribution, auditability, and architectural discipline.
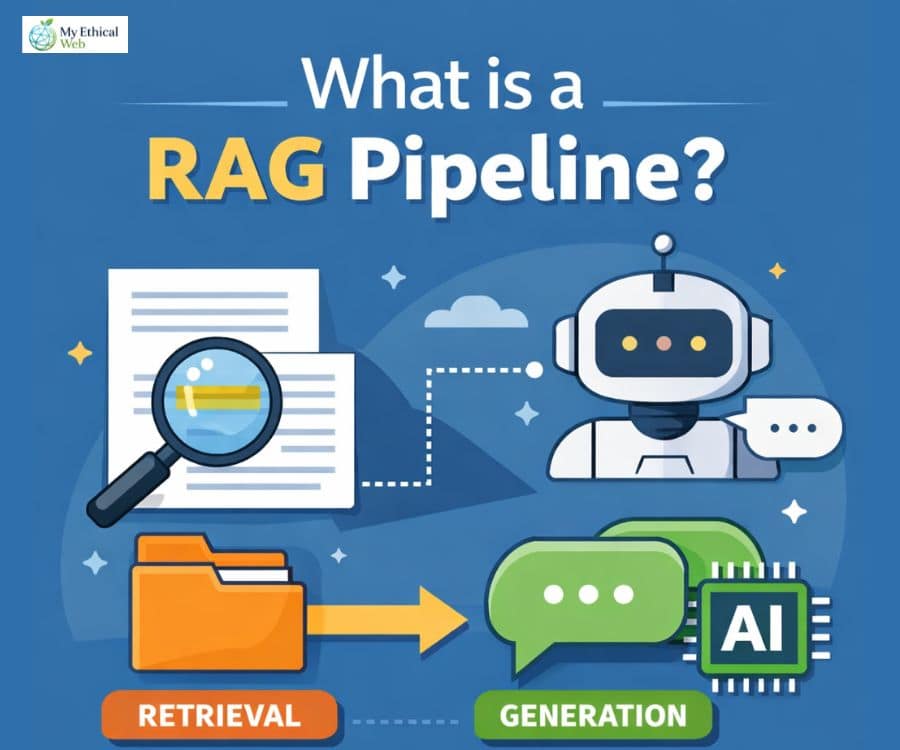
What Is a RAG Pipeline? (Here’s How I Frame It Clearly)
A RAG pipeline (Retrieval-Augmented Generation pipeline) is an AI architecture that retrieves relevant external documents before generating a response, grounding outputs in verifiable data instead of relying only on model memory.
The core flow:
- User query
- Query embedding
- Retrieval from vector or hybrid index
- Context injection into prompt
- LLM generation
- Optional citation + logging layer
Unlike standalone systems such as ChatGPT powered by OpenAI, a RAG system formally connects a retrieval engine to a language model.
However, in 2026, that distinction is blurring. GPT-5 Enterprise introduced an Auto-RAG toggle, meaning retrieval is now native in some enterprise configurations. The line between model and pipeline is becoming architectural rather than product-based.
KEY CONCEPT: Retrieval-Augmented Generation (RAG)
A system architecture where an AI retrieves relevant documents first, then generates responses grounded in that retrieved context, reducing hallucinations and increasing verifiability.
What Is the Difference Between LLM and RAG? (I Noticed the Debate Evolving)
An LLM generates text from trained parameters, while a RAG pipeline retrieves external data at runtime and injects it into the model before generation.
But here’s what changed in 2026:
- Large models are no longer the only focus.
- Retrieval quality often outweighs model size.
- Small Language Models (SLMs) are replacing massive LLMs in generation layers.
I had expected bigger models to remain dominant. Instead, many architectures now use smaller generation models paired with stronger retrieval—a shift that significantly reduces AI chatbot environmental impact.
Why?
Because when retrieval is high-quality, the model doesn’t need vast internal knowledge.
The 2026 Trend: Small Models Inside RAG
Many systems now deploy SLMs such as Phi-family models or compact Llama variants for generation after retrieval.
Observed benefits across documentation and vendor case material:
- Up to 60–70% cost reduction
- Lower latency
- Comparable accuracy in narrow domains
The reasoning is simple: if the retrieval layer provides precise context, the generation layer can be smaller.
Accuracy becomes a retrieval problem—not a parameter problem.
That inversion is one of the biggest architectural shifts of 2026.
Traditional RAG vs. Agentic RAG (This Is the 2026 Distinction)
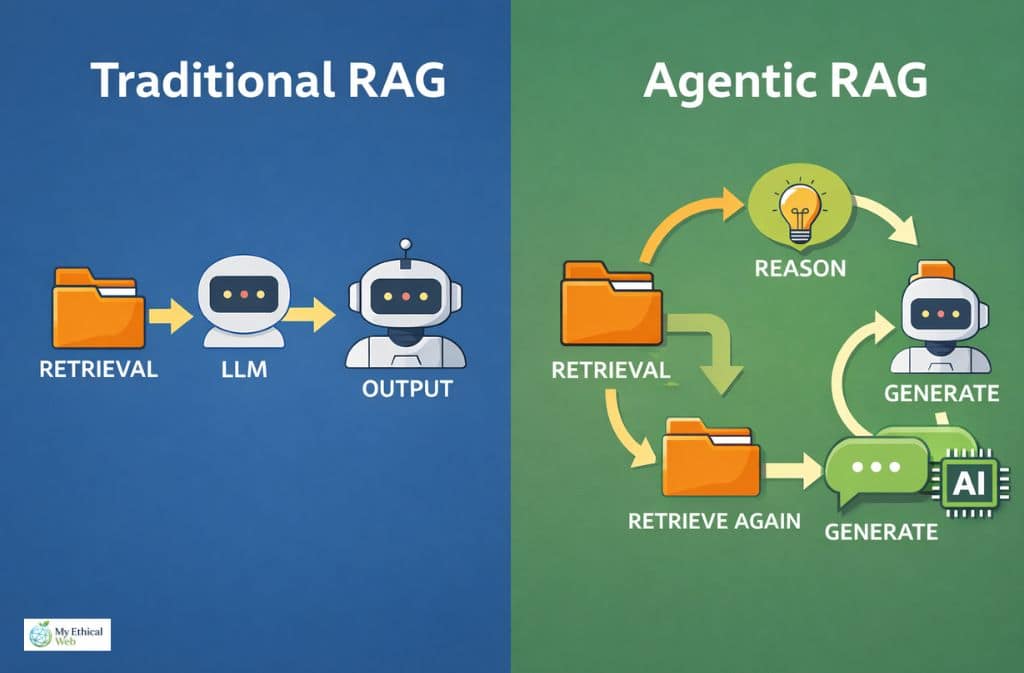
Traditional RAG uses a linear pipeline: retrieve once, generate once.
Agentic RAG introduces reasoning loops, multi-step retrieval, and dynamic query refinement before generation—an approach that shares conceptual similarities with AI agents vs chatbots in terms of autonomous decision-making capabilities.
Here’s the comparison:
| Feature | Traditional RAG | Agentic RAG |
|---|---|---|
| Retrieval Pattern | Single-pass | Multi-step iterative |
| Query Reformulation | No | Yes |
| Reasoning Loop | None | Yes |
| Best For | FAQs, policy Q&A | Complex synthesis, cross-doc analysis |
| Latency | Lower | Higher |
| Governance Logging | Moderate | More complex but richer |
I had expected linear RAG to remain sufficient. But for thematic questions—like “What risks appear across all 2025 contracts?”—single-pass retrieval struggles.
Agentic RAG performs iterative retrieval:
- Initial answer draft
- Gap detection
- Additional retrieval
- Revised synthesis
That loop is becoming the standard for enterprise synthesis tasks.
KEY CONCEPT: Agentic RAG
A retrieval-augmented architecture that includes reasoning loops, query reformulation, and multi-step retrieval before final generation.
Hybrid Search Explained Clearly (Because It’s Often Misunderstood)
Hybrid search combines:
- BM25 keyword search
- Vector semantic search
It does not mean two different models.
It means:
- Keyword matching captures exact terms.
- Vector similarity captures semantic meaning.
In 2026, hybrid search frequently outperforms vector-only retrieval for compliance, legal, and technical corpora.
Interestingly, vector-only systems struggle when terminology is rigid or regulated. Keyword signals still matter.
The Hidden Metadata Failure I Observed
A legal team attempted to deploy a RAG system in early 2026 without a structured metadata layer.
The retrieval worked. The answers looked confident.
But the system began referencing outdated tax clauses because it could not distinguish “Effective Date” metadata tags. It treated archived documents as current.
It was messy.
That situation reinforced something simple: metadata-first ingestion is not optional in regulated environments.
Without:
- Effective date tagging
- Version identifiers
- Jurisdiction labels
Retrieval accuracy becomes legally risky.
Regulatory Reality: Traceability Is Now Required
The European Commission AI Act enforcement phases in 2026 formalized documentation and traceability obligations for high-risk systems.
For many enterprise deployments, this now requires:
- Source attribution
- Retrieval logging
- Prompt auditing
- Data lineage transparency
Vendors such as Microsoft and Amazon Web Services have expanded enterprise logging capabilities in response.
Accuracy alone is insufficient.
Auditability is now structural.
GraphRAG: The Emerging Solution for Thematic Queries
Traditional vector search works well for fact retrieval.
It struggles with thematic or relational queries like:
- “What patterns exist across all contracts?”
- “Which vendors share similar risk clauses?”
GraphRAG introduces knowledge graph structures into the retrieval layer.
Instead of retrieving by semantic similarity alone, it retrieves based on:
- Entity relationships
- Structured links
- Cross-document connections
In 2026, this is increasingly used for:
- Legal analysis
- Financial risk mapping
- Enterprise policy synthesis
Vector search answers questions.
Graph-based retrieval answers relationships.
That distinction is subtle—but important.
Cold Start & “Re-Warming” in Multi-Cloud RAG
Multi-cloud RAG systems are now encountering “cold start” retrieval spikes.
When:
- Embedding indexes scale across regions
- Retrieval nodes spin down
- Vector caches expire
Initial queries can see latency increases.
Architectures now implement:
- Pre-warming strategies
- Cached embedding layers
- Persistent retrieval memory
I had expected generation latency to dominate performance tuning. Instead, retrieval warm-up behavior increasingly defines user experience in distributed AI systems.
Comparison of RAG Patterns
| Architecture | Strength | Weakness | 2026 Risk |
|---|---|---|---|
| Linear RAG | Fast, simple | Limited reasoning | Thematic blind spots |
| Agentic RAG | Deep synthesis | Higher latency | Governance complexity |
| Vector-Only | Strong semantic recall | Weak on structured terms | Precision loss |
| GraphRAG | Relational insight | Complex setup | Knowledge graph maintenance |
Each solves a different class of problem.
There is no single dominant architecture.
Mistakes I Observed Across Documentation
- Ignoring metadata tagging.
- Over-relying on vector similarity.
- Skipping audit logging.
- Treating SLMs as inferior by default.
- Forgetting effective-date validation.
- Failing to test thematic queries.
- Designing without governance in mind.
Most failures stem from retrieval design, not model intelligence.
Generative Engine Optimization (GEO) Check
If content is not semantically chunkable, it becomes difficult for RAG systems to retrieve it effectively.
Effective structure includes:
- H2 headings every 250–350 words
- Clear definition blocks
- Modular sections
- Concise summaries
RAG pipelines retrieve blocks—not essays.
Poor structure reduces AI visibility.
Well-structured content improves retrievability and citation likelihood in generative systems.
Formatting is now part of optimization.
FAQs
Q. What is a RAG pipeline in simple terms?
A RAG pipeline retrieves relevant documents first and then uses a language model to generate responses grounded in that information, reducing hallucinations and improving traceability.
Q. What is the difference between traditional and agentic RAG?
Traditional RAG retrieves once and generates once. Agentic RAG performs iterative retrieval and reasoning loops before final synthesis, making it better for complex cross-document analysis.
Q. What is hybrid search in RAG?
Hybrid search combines BM25 keyword matching with vector semantic similarity to improve precision and recall during retrieval.
Q. Is ChatGPT a RAG system in 2026?
Base ChatGPT is a language model interface, but enterprise configurations now include native retrieval features, narrowing the gap between model and pipeline.
What is GraphRAG?
GraphRAG integrates knowledge graphs into the retrieval layer to answer relational or thematic queries that vector similarity alone cannot resolve effectively.
Q. Why is traceability important in 2026?
Regulatory frameworks like the EU AI Act require source attribution and audit logging for certain AI systems, making traceable retrieval architecture essential.
Related: Rapid Web App Development in 2026: When Speed Stops Scaling